
RabbitMQ - Introduction et bonnes pratiques d'infrastructure
C'est quoi RabbitMQ® ?
Pour ceux qui ne connaissent pas l'outil, RabbitMQ est un logiciel open source, développé par Pivotal Software, Inc. Il s'agit d'un message broker (bus/agent de messages), très simple à mettre en place, multi-plateforme et multi-protocole (AMQP, MQTT, STOMP).
RabbitMQ est donc particulièrement adapté pour monter rapidement une architecture microservices ou IoT, nécessitant un bus de message pour garantir les communications entre les différentes briques de cette architecture.
C'est justement notre cas chez Lectra : nous disposons d'une architecture logicielle aux composantes très différentes (microservices, machines outils connectées, ...). Nous avons donc besoin de cette agilité, qu'on ne retrouve pas forcément dans les autres message brokers (ou agents de messages), mais aussi des garanties et des contrôles sur les transports des messages que nous n'aurions pas forcément avec des API REST.
Architecture et bonnes pratiques
Voici à quoi ressemble l'architecture RabbitMQ que nous utilisons :
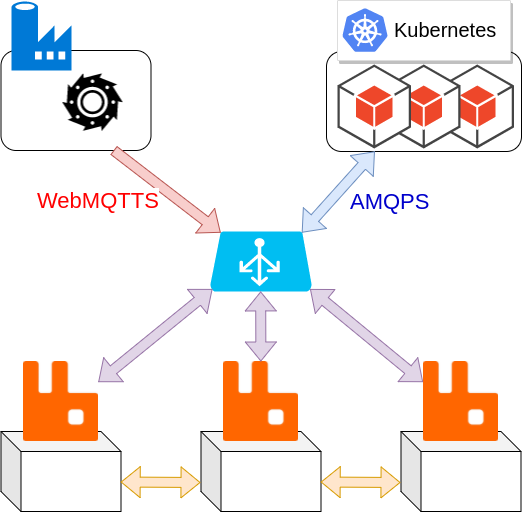
A première vue, c'est assez simple. Mais si vous vous demandez si nous n'aurions pas pu faire encore plus simple, alors cet article est fait pour vous ;-).
AMQPS / WebMQTTS
Les plus observateurs d'entre vous auront peut être remarqués le "S" à la fin des deux protocoles que nous utilisons pour faire communiquer nos services entre eux :
- AMQP / AMQPS
- WebMQTT / WebMQTTS
Vous l'aurez sûrement deviné, il s'agit de la déclinaison non-sécurisée/sécurisée (chiffrée) de chacun de ces protocoles.
Par défaut dans RabbitMQ, les échanges ne sont pas chiffrés. Bien qu'il n'y ait pas de réponse universelle à la question "dois-je chiffrer l'ensemble de mes flux ?", l'Ops que je suis ne peut pas s'empêcher de répondre par un grand OUI.
C'est particulièrement vrai dans notre cas, où une partie des flux transite par Internet, et l'autre transite à l'intérieur du réseau de notre cloud provider. L'ajout du chiffrement est obligatoire. Les risques d'espionnage, de détournement d'information, d'attaque du type Man in the Middle, ... sont suffisamment sérieux pour qu'on prenne le temps de configurer un chiffrement TLS.
Cependant, l'impact sur les performances globales de la plateforme est réel et devra être pris en compte lors du choix de l'architecture.
Comment activer le chiffrement TLS sur mes interfaces RabbitMQ ?
Tout se passe dans les fichiers de configuration. Il faudra déposer les fichiers de certificats (CA, certificat public et clé privée) et rajouter les lignes suivantes dans votre configuration :
[
{rabbit, [{ssl_options, [{cacertfile, "/path/to/testca/cacert.pem"},
{certfile, "/path/to/server_certificate.pem"},
{keyfile, "/path/to/server_key.pem"},
{verify, verify_peer},
{fail_if_no_peer_cert, true}]}]}
].Cependant, là aussi par défaut, il n'y a pas de restrictions sur les protocoles disponibles. Or, les failles sur SSL et TLS 1.0 de ces dernières années nous obligent à désactiver ces protocoles obsolètes (voire même TLS 1.1 aussi), ainsi que toutes les suites de chiffrements non sécurisés, ce qui va nettement complexifier notre configuration :
%% -*- mode: erlang -*-
[
{ssl, [
{versions, ['tlsv1.2']}
]},
{rabbit, [
{ssl_listeners, [5672]},
{ssl_options, [
{cacertfile, "/etc/rabbitmq/certs/cacert.pem"},
{certfile, "/etc/rabbitmq/certs/cert.pem"},
{keyfile, "/etc/rabbitmq/certs/key.pem"},
{versions, ['tlsv1.2']},
{ciphers, [
{ecdhe_ecdsa,aes_256_gcm,null,sha384},
{ecdhe_rsa,aes_256_gcm,null,sha384},
{ecdhe_ecdsa,aes_256_cbc,sha384,sha384},
{ecdhe_rsa,aes_256_cbc,sha384,sha384},
{ecdh_ecdsa,aes_256_gcm,null,sha384},
{ecdh_rsa,aes_256_gcm,null,sha384},
{ecdh_ecdsa,aes_256_cbc,sha384,sha384},
{ecdh_rsa,aes_256_cbc,sha384,sha384},
{dhe_rsa,aes_256_gcm,null,sha384},
{dhe_dss,aes_256_gcm,null,sha384},
{dhe_rsa,aes_256_cbc,sha256},
{dhe_dss,aes_256_cbc,sha256}
]},
{verify, verify_peer},
{fail_if_no_peer_cert, false}]}
]}
].A noter, depuis la version 3.7 de RabbitMQ (dernière version en date, la 3.8 sort bientôt), le format de la configuration a changé (erlang => sysctl) pour être plus lisible et plus simple à automatiser. Cependant, à ma connaissance, il n'est pas possible de configurer l'ensemble des limitations de ciphers/protocoles.
"While the new config format is more convenient for humans to edit and machines to generate, it is also relatively limited compared to the classic config format used prior to RabbitMQ 3.7.0."
Et pourquoi 3 noeuds et pas juste un, au milieu ?
Cette question se veut volontairement provocatrice !
Comme tout service informatique, les objectifs en terme d'indisponibilités tendent forcément vers 0. Un moyen classique d'approcher cet objectif est de redonder les composants informatiques, pour éviter tout Single Point of Failure.
Ca tombe très bien, puisque RabbitMQ propose nativement un mécanisme de clustering. Et comme dans tout cluster disposant d'un mécanisme de vote/d'élection, il est fortement conseillé d'avoir un nombre impair de noeuds pour résoudre les cas de split brain (la majorité l'emporte en cas de partition réseau). D'où les 3 noeuds (mais on peut en avoir 5, 7, ...).
Le clustering dans RabbitMQ, comment ça marche ?
Pour simplifier notre vie, le cluster RabbitMQ agit de telle sorte que tous les objets logiques (utilisateurs, queues, ...), où qu’ils soient, sont connus et adressables depuis tous les membres (attention, je n'ai pas dis répliqués, on y reviendra).
Ca, c'est super pratique. Quel que soit le noeud qu'on va contacter, si la queue est présente sur un autre serveur RabbitMQ, le message sera redistribué de manière transparente vers le noeud qui possède la queue.
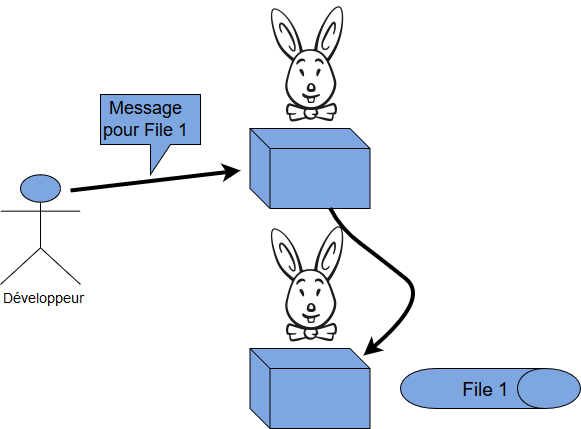
Pour "masquer" la complexité induite par l'ajout de serveurs RabbitMQ supplémentaires, on a donc juste à ajouter un loadbalancer en amont du cluster. Le développeur envoie simplement le message au loadbalancer. Peu importe le noeud sur lequel le message sera réellement envoyé ensuite, il sera transféré instantanément.
Comment démarrer un cluster ?
Sans rentrer dans le détail de toutes les opérations nécessaires pour bootstrapper un cluster, ce qu'il faut savoir c'est que tous les noeuds doivent évidemment pouvoir se contacter et si possible être relativement proches (en terme de latence).
Les serveurs RabbitMQ doivent être configurés de manière à partager une même passphrase dans le fichier /var/lib/rabbitmq/.erlang.cookie, et on doit ensuite joindre un des noeuds depuis les deux autres avec la commande suivante :
#sur le noeud rabbit2, puis rabbit3
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@rabbit1Pour la procédure complète, je vous invite à consulter la documentation qui est très bien écrite.
Maintenant, on est hautement disponible ?
Vous vous dites : "Chouette ! J'ai un cluster ! Je suis hautement disponible !"
Et bien... non.
Un point pouvant induire une grande confusion dans RabbitMQ est la terminologie "cluster RabbitMQ". Le fait de monter un cluster laisse penser que tout devient automatiquement hautement disponible.
Or, en réalité, comme je l'ai écrit plus haut, il s'agit uniquement de rendre accessible et addressable l'ensemble des objets logiques depuis tous les noeuds. En revanche, les queues, et a fortiori leur contenu, ne sont physiquement présentes que sur un noeud et un seul.
Ainsi, si un noeud du cluster disparaît, toutes les queues qu'il possède seront détruites (si elles sont Transient), ou bloquées jusqu'à ce que le noeud soit de nouveau disponible (si elles sont Durable).
Dans tous les cas, il y aura interruption de service et éventuellement perte de messages, malgré le fait qu'on ait un cluster !
Haute disponibilité des queues
Heureusement, il est également possible de répliquer les queues et leur contenu sur une partie ou la totalité des noeuds disponibles dans le cluster. On dispose alors d'une queue principale et de miroirs qui pourront prendre le relai en cas de défaillance d'un noeud.
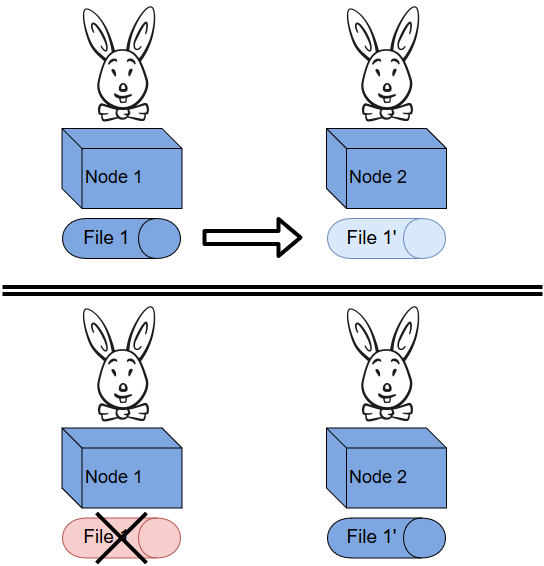
Ceci est configurable, par queue ou par policy (applicable à toutes les queues correspondant au pattern), avec les options ha-mode, ha-params et ha-sync-mode.
- ha-mode
- all : synchronisera votre queue sur des miroirs présents sur tous les noeuds du cluster
- exactly : permettra d'indiquer, en positionnant également un nombre sur ha-params, le nombre exact de noeuds sur lesquels les queues sont répliquées
- nodes : synchronisera des miroirs sur une liste de noeuds explicitement nommés
- ha-sync-mode
- automatic : en cas d'apparition d'un nouveau miroir, tous les messages sont synchronisés immédiatement
- manual : en cas d'ajout d'un nouveau miroir, seuls les nouveaux messages sont synchronisés
Attention au mode automatic, surtout en conjugaison avec le ha-mode à all. En effet, si ce mode est plus sécurisé puisqu'il garantit que tous les noeuds ont bien la totalité des messages, il a aussi l'inconvénient de bloquer les queues "à synchroniser" (tant que l'ensemble des messages ne sont pas répliqués partout).
Dernier point d'attention, au même titre que le chiffrement, l'ajout de la haute disponibilité (et du clustering, dans une moindre mesure) a un impact sur les performances globales de la plateforme.
Conclusion
RabbitMQ est un outil puissant et extrêmement simple à mettre en place. On peut le lancer et obtenir un broker de message robuste avec une simple commande "docker run".
docker run -d --hostname my-rabbit --name some-rabbit rabbitmq:3Pour autant, dans un environnement de production avec des objectifs en terme de haute disponibilité, il n'est pas si trivial de trouver les bons paramètres. Certains nécessiteront un peu de recherche et de configuration erlang, d'autres nécessiteront un peu de benchmarking et de tuning, si les performances commencent à devenir un problème.
Pour cette seconde catégorie, nous y reviendrons dans un autre article. Cependant, sachez quand même qu'on peut traiter sans trop de difficulté des milliers de messages par secondes, même avec des machines disposant de peu de CPU. Vous aurez sûrement le temps de voir venir ;-)...