

Introduction
Il y a quelques années, nous avons adopté à Lectra React/Redux comme stack de référence pour nos nouveaux développements de front-ends. Un avantage majeur de cette stack réside dans le fait que c'est l'une des plus utilisées à l'heure actuelle. La documentation est donc extrêmement bien fournie, qu'il s'agisse de documentation officielle, d'articles ou de réponses à des problèmes fréquents (StackOverflow et autres). Nos équipes ont été formées pour et sont productives avec : les concepts étant naturels, elles savent rapidement se repérer au sein d'une base de code avec laquelle elles ne sont pas familières.
Apparition de complexité
Cependant, tout n'est pas rose avec cette stack. Au fur et à mesure qu'une application grossit, même s'il est encore possible de se repérer au sein de son architecture, il devient progressivement difficile d'apporter des changements. En effet, même si l'utilisation de Redux permet de facilement tester unitairement le comportement de l'application, le nombre d'indirections et de composants impliqués dans la réalisation d'une action est tel que faire du refactoring (extraire ou remplacer une section par exemple) peut devenir très difficile. Cela s'explique par le fait que les composants, qui semblent découplés, continuent d'être très liés les uns aux autres par des relations entre événements (plutôt que par des appels de fonctions).
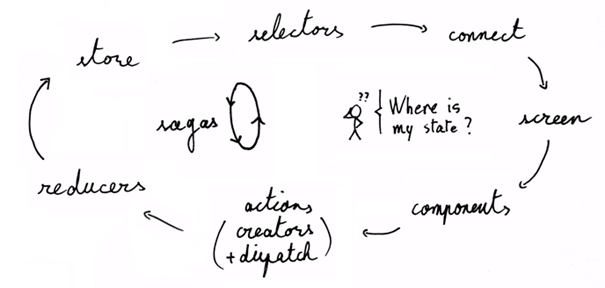
Un peu trop d'indirection ?
Retour à la simplicité ?
Face à ces problématiques, il a été tenté, pour quelques applications, de repartir sur une architecture plus simple : React sans Redux. L'objectif était de retourner aux sources pour réellement identifier les besoins plutôt que d'appliquer sans réfléchir un pattern. Nous avons hélas constaté une dérive importante dans la construction de ces applications : les composants sont devenus trop "intelligents", regroupant dans le même code la gestion d'éléments graphiques et de règles métier, et même des appels réseau. Le code mélangeant l'affichage et le backend, il devenait difficile à maintenir et faire évoluer.
Les composants en question ont rapidement atteint des tailles déraisonnables. Au lieu de composants graphiques simples, des composants "écran" commençaient à tout gérer.
Un composant qui a grossi.
De plus, à cause du mélange entre code métier, d'affichage et d'infrastructure, les tests devenaient pénibles, conduisant à un manque de couverture sur les parties les plus complexes.
D'autre part, pour pallier à la difficulté d'extraire des éléments, de la duplication de code issu de ces gros composants est apparue, entraînant des appels réseaux dupliqués et autres causes de perte de performance par manque de partage d'information entre les composants.
La conclusion de ces expérimentations a logiquement amené à la ré-introduction de Redux dans la stack.
Afin de réduire cette complexité et ainsi faciliter la compréhension et la manipulation de la base de code, d'autres solutions ont été trouvées. TypeScript en fait partie, et a déjà été utilisé à Lectra sur certains backends NodeJS.
Retour à la stack initiale, mais avec TypeScript
Côté React
Dans un premier temps, il a été décidé de mettre en place une stack TypeScript + React sur un nouveau projet afin de tester la stack sans complexité liée à du code existant. Le démarrage d'un nouveau projet a été l'occasion de tester la dernière version de React équipée des Hooks, une avancée qui améliore aussi la lisibilité du code.
Le système de PropTypes de React est relativement redondant avec la déclaration de types proposée par TypeScript. La nuance entre les deux est dans leur exécution : TypeScript effectue sa vérification à la compilation alors que les PropTypes sont vérifiées à l'exécution. TypeScript offre donc des garanties plus intéressantes, qui assurent que tous les cas sont couverts alors que les PropTypes ne remonteront des erreurs que si elles sont rencontrées par le développeur quand il utilise l'application. Par ailleurs, là où les PropTypes ne sont que peu contraignantes sur les objets profonds (car le développeur ne type pas toujours en détail le contenu des tableaux et objets), TypeScript force à explicitement indiquer le type complet sauf marquage contraire explicite. Notons que nous utilisons TypeScript en mode strict, ce qui conduit à réellement typer la majeure partie de notre code. En complément, les déclarations des types permettent une meilleure auto-complétion dans l'éditeur, et avec le support natif de TypeScript par Visual Studio Code, l'expérience de développement est excellente.

Des props plus lisibles et plus précises qu'avant.
Au-delà de ce changement, on constate une différence notable par rapport aux habitudes de développement : dès lors que l'on utilise une bibliothèque, il faut s'assurer qu'elle vienne bien avec des déclarations de types (inclues ou installées séparément), quitte à devoir les créer nous-mêmes. Cela se fait facilement, fort heureusement, et nous avons ainsi progressivement typé les composants de notre bibliothèque interne de composants graphiques qui reste écrite en JS à l'heure actuelle.
Côté Redux
Là où les changements sont plus importants, c'est sur la partie Redux. En effet, l'utilisation de types pour les actions et les reducers permet un support éditeur et des vérifications de cohérence jusque là impossibles. Il y a donc un gain important de ce côté, notamment quand on utilise le support des unions tagguées de TypeScript.
Concernant les déclarations d'actions, nous avons fait le choix de ne pas utiliser de bibliothèques externes, préférant garder la simplicité de déclaration que nous avions en JS avec des action creators qui sont de simples fonctions retournant des objets. Afin de bénéficier du système d'unions typées, nous avons regroupé les actions dans des unions en s'assurant que TypeScript repère bien le champ type permettant de discriminer toutes les combinaisons de champs possibles.
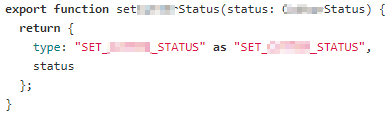
"XXX" as "XXX" permet que le type du champ type soit "XXX" plutôt que string.
Dans les reducers, le fait d'avoir correctement typé les actions permet d'avoir une vérification complète des champs présents dans les actions à l'intérieur de chaque case du switch(action.type), ce qui, combiné avec la déclaration du type du state, facilite grandement l'écriture des reducers.
La déclaration des sélecteurs est triviale en TypeScript puisque tous les accès au state des reducers sont vérifiés, ce qui permet de faire aisément des refactorings sans briser l'interface exposée aux autres composants.
Orchestration : sagas vs epics
Pour les cas où une action doit conduire à des effets de bords comme des appels à une API, nous avions l'habitude de passer par Redux Saga, mais l'absence de typage correct dans Saga nous a conduit à expérimenter l'utilisation de la bibliothèque Redux Observable, qui n'a pas été concluante. Le problème majeur que nous avons rencontré est qu'elle est intrinsèquement complexe car RxJS, la bibliothèque sur laquelle elle s'appuie, est elle-même complexe dans son utilisation.
La bibliothèque RxJS est extrèmement puissante, nous l'utilisons d'ailleurs sur certains services backend qui ont des besoins d'orchestration et de résilience. Mais pour accomplir des tâches simples, la syntaxe et les opérateurs sont obscurs en première lecture. Avec cette prise en main complexe, on ressent directement la nécessité de former les équipes pour qu'elles soient productives : le fait de devoir suivre une formation pour écrire un hello world est rédhibitoire.
Par ailleurs, l'écriture de tests unitaires avec RxJS est particulièrement complexe car il faut gérer l'orchestration des streams... et même avec les marble diagrams, cela reste "too much". En effet, nos besoins tournent principalement autour d'appels REST et de logique simple. Et tout n'est pas rose du point de vue support des types avec RxJS car l'inférence de types se perd fréquemment (la compilation fonctionne mais l'auto-complétion est perdue), ce qui n'aide pas alors que l'API est déjà complexe. La surcouche fournie par Redux Observable n'est pas exempte de problèmes non plus, par exemple la fonction de filtrage ofType n'a pas correctement fonctionné pour nous : TypeScript n'a pas reconnu la discrimination entre nos types d'actions, ce qui nous a forcé à employer des contournements pour cette brique de base. Ce point là est probablement corrigé par l'utilisation d'une bibliothèque compagnon recommandée, mais que nous n'avons pas souhaité adopter car elle change toutes les déclarations d'actions / action creators.
Faute d'alternative, nous sommes donc revenus à l'utilisation de Redux Saga, qui faisait déjà partie de la stack de nos projets React/Redux antérieurs. Il n'y a pas de différence dans l'utilisation de Saga en TypeScript par rapport à son utilisation en JS. Cela étant dit, le fonctionnement intrinsèque de Saga ne nous permet pas d'exploiter correctement le système de type. Ainsi tous les appels à select(), call() et autres perdent toute information de type. Cela est dû à la construction des sagas qui se fait en déclarant des générateurs avec function* et en utilisant yield pour communiquer avec le moteur d'exécution des sagas. Le compilateur TS n'ayant pas de garantie que ce soit réellement Saga qui appellera nos générateurs, il ne peut pas considérer que les retours des yield sont typés. On voit donc apparaître des types any un peu partout. Ce n'est pas très satisfaisant, mais ce n'est pas bloquant (a contrario, la mauvaise inférence avec ofType dans Redux Observable causait des erreurs).
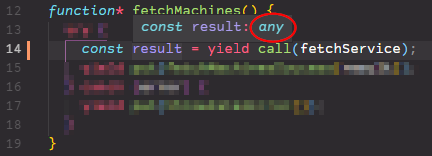
Pas de vérification des types des entrées-sorties effectuées via yield.
Mélanger JS et TS, ou comment faire du neuf avec du vieux
Après avoir testé cette stack sur une application fraîchement créée, nous avons commencé la migration d'une application existante de taille moyenne. Une première partie de la migration a tourné autour de la bascule de JavaScript à TypeScript. Le support de fichiers des deux langages dans le même projet nous a fourni un confort important lors de cette étape. En effet, nous avons converti progressivement différentes sections de l'application, sans avoir à tout faire d'un seul coup. Une deuxième partie de la migration concerne le rajout de Redux et Saga, comme évoqué précédemment, qui commence juste à l'heure où j'écris ces lignes.
Conclusion
Il est indéniable que toute application devient complexe au cours du temps, l'ajout de fonctionnalités étant notre activité principale de développeurs. Cette complexité doit être gérée de sorte à ce qu'il soit aussi facile de faire ces ajouts et modifications après quelques années qu'au début d'un projet. Pour cela, il est indispensable de pouvoir facilement se repérer dans du code qui n'est plus dans la mémoire collective de l'équipe. Cela veut dire pouvoir le lire et le comprendre, le modifier ou le supprimer. Même si les tests unitaires permettent de vérifier le bon fonctionnement du code et peuvent éventuellement servir de pseudo-documentation de son comportement, ils ne permettent pas d'aller aussi loin qu'un système de type. Comprendre une fonction est très différent de comprendre la structure des données manipulées (que prend une fonction en entrée ? que produit-elle en sortie ?). En général, quand on aborde une section de code inconnue, c'est pourtant cela que l'on cherche en premier ! React permet déjà de s'orienter dans cette direction avec les prop types, mais ce système est insuffisant et l'introduction de TypeScript permet d'aller plus loin dans le typage sans changer radicalement ses outils. Basculer sur TypeScript se fait relativement facilement, qu'il s'agisse d'un nouveau projet ou d'un projet avec du code existant grâce au typage progressif. La plupart des bibliothèques utilisées habituellement viennent avec des déclarations de types permettant une transition sans accrocs (avec un bemol pour Saga). Sans lister exhaustivement les nombreux avantages d'un langage fortement typé, l'ajout de types facilite la navigation dans le code, l'écriture de code neuf au milieu de code plus ancien, l'évaluation des impacts d'un refactoring et bien-sûr la détection de bugs. Ceux qui souhaiteraient aller plus loin dans la direction d'un code totalement typé pourront s'orienter vers des solutions plus avancées comme ReasonML ou Elm.
Bonus : organisation des sources
Une dernière problématique que nous avons souhaité résoudre dans nos projets est la navigation dans le code source. Par le passé, nous avions une organisation hiérarchique familière de tous ceux qui ont travaillé sur des projets MVC avec un dossier pour chaque type de module. Ainsi, nous avions des dossiers ui/components, ui/screens, reducers, constants, actions, sagas, et ainsi de suite. A l'intérieur, on retrouvait un mélange de fichiers issus de morceaux différents de l'application. Quand un développeur travaillait sur une feature, il devait jongler entre un ou plusieurs fichiers de chaque dossier. La tentative que nous avons entreprise est de maintenant regrouper les fichiers par features, de sorte à facilement identifier le périmètre sur lequel chacun travaille. Ainsi, nous avons mis en place des dossiers tels que authentication, menu, et ainsi de suite. Les merge requests concernent ainsi en général un seul dossier au lieu de... tous ! Il est plus facile de retrouver son chemin quand tous les fichiers liés sont colocalisés, et on peut dire adieu aux longs import "../../../../foo/bar".
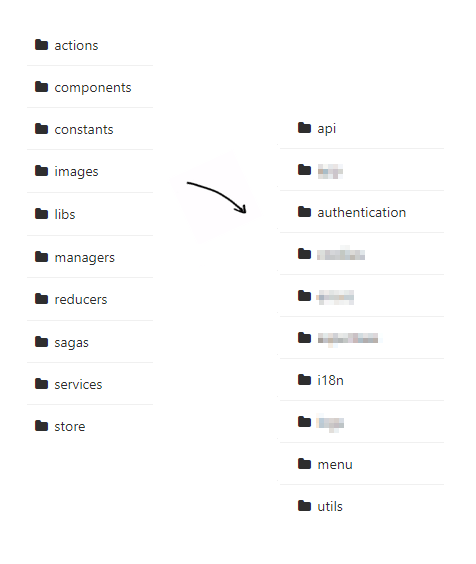
Comparaison avant/après entre dossiers génériques et spécifiques.