

My colleague and I from Lectra had the opportunity to participate (virtually) in this year's Data+AI Summit organised by the company Databricks. This summit is one of the biggest Data related conferences in North America. Spread over a week, we had the chance to follow two days of workshops on specific topics and three days of keynotes and conferences.
The Keynotes
The Keynotes have been very interesting, with very exciting announcements for open source and Databricks and with renowned guests like Bill Nye, Malala Yousafzai and the NASA Mars Rover team. The following are highlights of the top announcements and innovations regarding Data and Databricks:
- Delta.io → https://delta.io/
With the release of Delta Lake 1.0.0, Databricks intends to improve many aspects of data lakes including, data quality, performance and governance. New features have also been included in the release. For example, Generated Columns, support for Spark 3.1, Connectors etc. - Delta Sharing → https://delta.io/sharing/
This is a brand new open source project that allows users to share data via an open and secure protocol between data lake of various Cloud providers, on-premises storage, and systems such as Tableau, Pandas etc. - Unity Catalog → https://databricks.com/product/unity-catalog
Databricks introduced a new tool for companies to maintain governance of their data: Unity Catalog. It’sthe first industry unified catalog for lakehouse, available across all clouds. You can use ANSI SQL queries to access your models and also provide audit logs to show who has access to what. - Databricks Machine Learning
New tools and features have been announced in the data science fields, to bring support to the full ML lifecycle. For example:
○ MLFlow to manage the lifecycle of ML projects → https://mlflow.org/
○ AutoML to quickly build and deploy ML models →https://docs.databricks.com/applications/machine-learning/automl.html
○ Feature Store to explore and create features simply →https://databricks.com/product/feature-store
○ Integration of Koalas (Pandas) into Spark → https://koalas.readthedocs.io/en/latest/
Workshops
I attended two interesting workshops in the first two days.
The first one was on Performance Tuning in Spark. For those who have not heard of Spark before, Apache Spark is an open source engine for fast analytics used in the fields of big data and machine learning with built-in support for Scala, Java, R and Python. Based on Resilient Distributed Datasets, it can process a lot of data in a distributed and fault tolerant way. It’s a great tool to work on your data, but it can come with some pitfalls. During the workshop we explored those issues and how to mitigate them.
Globally, five performance problems can be occur while running Spark:
- Spill problems: When your data is too large to fit in RAM, so temporary files are written to disk which can lead to OOM errors.
- Skew problems: You have an imbalance in the size of partitions.
- Shuffle problems: Too much shuffling and I/O calls as a side effect of wide transformations.
- Storage problems: When you have too many tiny files or issues with data ingestion.
- Serialization problems: When using UDF (User Defined Functions) limits optimization.
These main issues can of course appear at the same time and be tangled together, which makes them difficult to diagnose. Benchmark functions like count, foreach and noop can be used to identify and mitigate these problems. So what are the solutions?
- In the case of Skew data, you can either use a salt to your skew column, you can optimize your joins or even better you can use a recent feature of Spark 3 called Adaptive Query Execution (AQE). AQE is a feedback loop with ML, that will optimize the job execution and reduce skewing by fine tuning and learning from the data.
- For Spill problems, you can increase the memory of your cluster per worker and apply a better management of your number of partitions or even repartitioning.
- For Shuffle issues, one way is to use fewer but larger sized workers, this will reduce the amount of data sent from one worker to the other. You can also try to reduce as much the amount of data to shuffle by applying filters and denormalizing your data. As well if possible broadcast small tables that will send all the data to all the workers.
- For Storage problems due to tiny files, DeltaLake has the advantage of autocompaction and auto optimization using AQE. If you don’t use DeltaLake, then a manual compaction algorithm will be necessary, but can be tricky to implement. For ingestion issues, try to provide a schema and use tables every time, or use DeltaLake (these features come by default).
- For Serialization issues, simply don’t use User Defined Functions. Spark sees them as black boxes and has no idea how to optimize them.
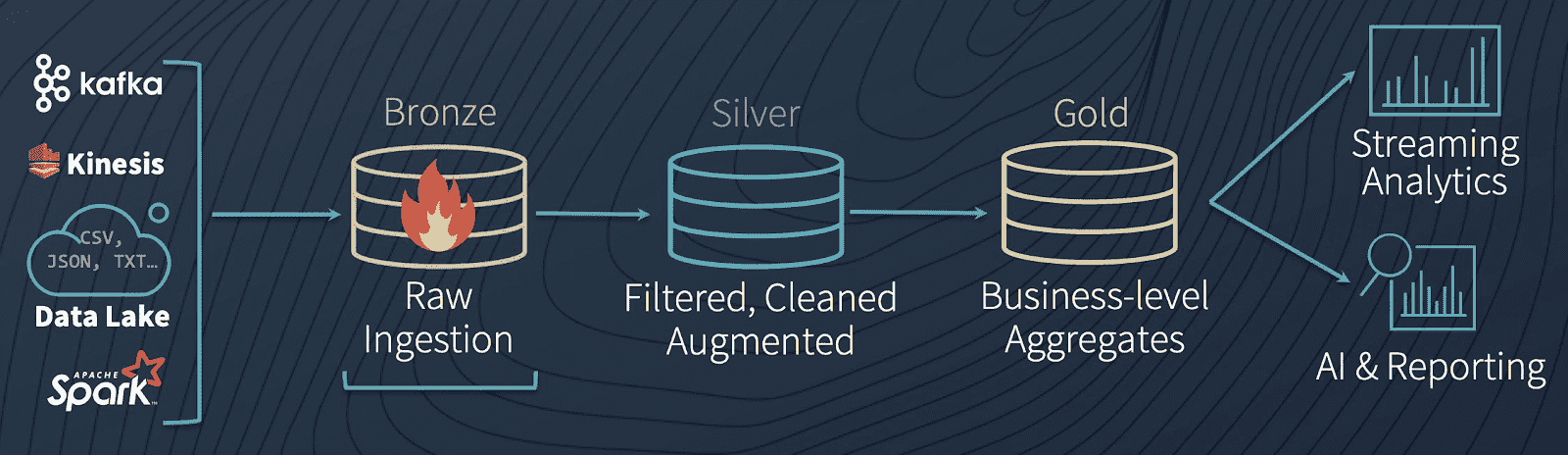
The second workshop named "Data Engineering with a LakeHouse" was mostly a presentation of Delta Lake as the main tool of a LakeHouse architecture. Building a reliable and robust end to end batch and streaming OLAP pipeline have been greatly facilitated by the arrival of Delta Lake. Challenges like appending data, handling historical data, data quality, performance, etc... can be resolved by the use of this new technology developed by Databricks. DeltaLake becomes the single source of truth in your organization thanks to features likes:
- ACID transactions
- Scalable Metadata
- Streaming and Batch unification
- Schema inforcement and schema evolution
- Time travel for historical data
- Upsert and Delete
Delta Lake is composed of three main components: the Delta Lake Storage Layer - highly performant, persistent and scalable, all at low cost, the Delta Tables - to record all metadata and transaction logs, all in parquet format, and the Delta Engine for file management and auto optimization of writes and caches. A common LakeHouse design solution was presented (see below) followed by a hands-on exercise.
Conferences
A lot (really a lot) of sessions of thirty minutes have been proposed during the last 3 days of the week with topics going from AI to Data Engineering, SQL Analytics and BI, Apache Spark, Databricks, Machine Learning etc. Companies like Microsoft, CERN, Databricks, Atlassian, Salesforce etc presented their recommendations or methods to achieve best results in their respectives projects. Unfortunately, I did not find the sessions I watched very interesting. I don’t know if it was due to the time difference (the summit was held in California, so we had 10 hours time difference) which made most sessions run very late during the day, or if it was a reduce attention on my part after watching the 2-3 hours keynotes, or if the video format made the speakers very passive in their presentation, probably it was a bit of the three. As well, in my opinion, too many choices was detrimental to the viewer. I had a very difficult time picking the sessions I wanted to attend. Many subjects seemed interesting but also overlapping which kind of made me jump from session to session, either missing the end or the beginning of the presentation. Finally, despite having some chatting channels to talk with other participants, the all virtual conference lacked those interactions you can have during an on-site summit, where you can go to company's booths, get goodies (of course!) and talk with peers.
Conclusion
Retrospectively, I do not think I will attend another all virtual summit in the future and definitely not one with a time difference so large. The online event being free to attend, all sessions and keynotes are available to anyone on YouTube. If Databricks interests you, I do encourage you to watch the Keynotes, a lot of announcements and great content there. Also I would recommend the workshop, even if virtual. It has a more in depth look at Spark and DeltaLake, where I did learn new things.