

Introduction
Dans cet article nous allons étudier l’intérêt de la librairie Reactor RabbitMQ au travers d’un exemple concret.
RabbitMQ est un broker permettant à des services de communiquer de manière synchrone ou asynchrone via des messages selon le protocole AMQP. Chaque service peut se connecter au broker et définir des exchanges et des queues, autrement dit des topologies, qui serviront à router les messages.
On qualifie un service de réactif lorsqu’il suit les principes définis dans le manifeste réactif, qui portent aussi bien sur l’architecture entre les applications qu’au sein même des applications. On pourrait résumer le mot réactif par la capacité à s’adapter à des charges de requêtes irrégulières automatiquement et via une utilisation plus efficace des ressources du système.
Reactor est une implémentation en java suivant ces principes réactifs et Reactor RabbitMQ en reprend les entités.
Nous verrons d’abord un résumé des principes du manifeste réactif, suivit d’une introduction au framework Reactor et enfin un exemple d’utilisation de Reactor RabbitMQ.
Le manifeste réactif
Pour satisfaire les exigences grandissantes des utilisateurs en terme de performances, un système doit assurer la continuité du service même sous une forte demande.
Le manifeste décrit les systèmes comme devant toujours être disponibles pour répondre, être robustes, souples et orientés message.
La disponibilité est la capacité à répondre rapidement et de manière continue aux requêtes. La robustesse signifie que le crash d’un service ne paralyse pas les services qui en dépendent. La souplesse est la capacité du système à mettre automatiquement en place les ressources nécessaires pour faire face à un pic de charge. Enfin, et surtout ce qui nous intéresse dans le cas de RabbitMQ et de Reactor: la communication orientée message est un moyen pour atteindre ces objectifs.
Les applications doivent communiquer de manière asynchrone entre elles mais aussi au sein même du code.
Le manifeste mentionne notamment deux avantages de la communication orientée message:
-
La remontée de la contre-pression (ou backpressure).
-
L' économie de ressources.
Pour comprendre ce qu’est la contre-pression, il faut distinguer les services en amont, c’est à dire qui produisent de la donnée, des services en aval qui consomment ces données. La contre-pression est la possibilité d’un service en aval de remonter le nombre de messages à produire à la source. Si le service en aval est saturé, il pourra ainsi demander moins de messages au service en amont. La contre-pression permet de rendre le système plus résilient en évitant aux services en aval d'être saturés.
L'économie de ressources consiste au niveau applicatif à ne pas épuiser le nombre de threads disponibles, donc à en bloquer le moins possible.
Nous allons voir plus en détail comment Reactor permet de gérer ces deux aspects.
Le framework Reactor
C’est un framework qui implémente la Reactive Streams specifications. La Reactive Streams Specification suit les principes du manifeste reactif en Java. Cette spécification définit des streams avec deux aspects supplémentaires: l’exécution asynchrone et la gestion de la contre-pression. Les tests de la spécification, appelés TCK, assurent que chaque implémentation satisfait la remontée de la contre-pression. Reactor est une des implémentations satisfaisant le TCK. L’avantage de cette norme est d’assurer l’interopérabilité entre les différentes librairies réactives en Java: utiliser Reactor avec une autre librairie se conformant à la Reactive Streams Specification dans la même application est ainsi possible.
Pourquoi utiliser Reactor?
Imaginons ce fragment de code appelant un service pour afficher une destination de vacances au hasard :
val service = DestinationService()
val destination = service.nextDestination()
println(destination)
println(destination.substring(0..2))
class DestinationService {
private val DESTINATIONS = listOf("Paris", "London", "Edinburgh", "Los Angeles", "San Francisco", "Atlanta", "New-York")
fun nextDestination(): String {
Thread.sleep(500) // Simule un appel réseau long
return DESTINATIONS.random()
}
}Le thread bloque à l’appel au service des destinations pour simuler une latence. On pourrait pallier à ce problème en passant un callback à un thread pour réaliser l’appel bloquant au service en asynchrone. Néanmoins nous bloquerons toujours un thread à chaque appel, or les threads sont une ressource finie:
val service = DestinationService()
val thread = Thread {
val destination = service.nextDestination()
println(destination)
println(destination.substring(0..2))
}
thread.run()De plus, on risque en pratique de transmettre le code métier comme callback dans de nombreux les traitements, rendant le code plus complexe à lire et moins fiable. On peut qualifier ce code d'impératif car on force explicitement le bloquage dans l’attente de nouvelles données.
Plutôt que de mélanger à la fois le code métier et d’imposer le flot de données, Reactor propose de séparer deux responsabilités:
-
la production des données
-
la description des opérations à enchaîner sur les données
Ainsi, le développeur décrit un ensemble d’opérations à effectuer de manière asynchrone, sans se soucier du moment où elles sont déclenchées. La production des données est prise en charge par les Publishers qui vont appeler les opérateurs dès que nouvelles données sont disponibles.
L’avantage de ce découpage, est de pouvoir composer facilement l’ensemble des opérations via des opérateurs, ce qui est plus lisible que de passer des callbacks entre les différents services. Surtout, la production des données vient souvent des interfaces avec les autres services comme dans notre exemple. Si le réseau est instable ou si les services que nous écoutons sont saturés et mettent du temps à répondre, on risque d’avoir des bloquages de threads. Des librairies réactives pour gérer chaque type d’interface (AMQP, HTTP, bases de données…) et produisant des données de manière non bloquante ont donc été développées.
Exemple d’utilisation de Reactor
Nous pouvons réécrire le service précèdent en s’appuyant sur les entités de Reactor. D’abord décrivons la source des données. Notre service renvoie maintenant un Publisher de type Mono (en 1 ci-dessous). C’est à dire un publisher publiant exactement 1 évènement. Un évènement peut soit contenir une donnée soit être en erreur, dans notre cas il contiendra toujours un nom de ville au hasard :
class ReactiveDestinationService {
private val DESTINATIONS = listOf("Paris", "London", "Edinburgh", "Los Angeles", "San Francisco", "Atlanta", "New-York")
fun nextDestination(): Mono<String> { <1>
return Mono.just(DESTINATIONS.random()).delayElement(Duration.ofMillis(500))
}
}Maintenant que nous avons défini le publisher, nous pouvons l’appeler (1) puis écrire notre logique métier via des opérateurs (2).
val reactiveService = ReactiveDestinationService()
val holidayMono = reactiveService.nextDestination() <1>
.doOnNext { <2>
println(it)
}.map {
it.substring(1..2)
}.doOnNext {
println(it)
}La description des opérations est asynchrone, rien n’est éxécuté dans un premier temps, c’est la phase d’assemblage. Pour déclencer l’exécution du Flux on y souscrit via la méthode subscribe():
println("Before subscribe")
holidayMono.subscribe()
println("After subscribe")On obtiendra la sortie suivante:
Before subscribe
After subscribeIl y a un souci, rien ne s’affiche!

C’est normal, l’exécution du code se fait de manière asynchrone en interne par Reactor pour ne pas bloquer le thread sur lequel est fait la souscription. Pour notre exemple seulement, on peut forcer cette exécution à bloquer via un countDownLatch.await() 1:
println("Before subscribe")
val countDownLatch = CountDownLatch(1)
reactiveService.nextDestination().doOnNext {
println(it)
}.map {
it.substring(0..2)
}.doOnNext {
println(it)
countDownLatch.countDown()
}.subscribe()
countDownLatch.await() <1>
println("After subscribe")On a alors la sortie voulue :
Before subscribe
Atlanta
Atl
After subscribeLe blocage d’un thread devient encore plus critique lorsque l’ensemble de l’application est construite pour être non bloquante. Par exemple, Reactor Netty est un serveur HTTP réactif qui démarre par défaut avec un thread par cœur de CPU. Il a donc souvent entre 4 et 8 threads au total dédiés au traitement des requêtes HTTP : traitement métier et envoi de la réponse. Ce type de serveur ne verra pas son nombre de threads augmenter avec les requêtes. Il serait donc catastrophique de bloquer un thread dans une application de ce type. En fait, lorsqu’on commence à utiliser une librairie non bloquante, toute l’application doit être non bloquante.
Gestion de la contre-pression
Nous avons vu que Reactor permet au Publisher de pousser de la donnée. En revanche, les consommateurs peuvent aussi être submergés par la quantité de données à traiter. Reactor permet au consommateur de réguler le flot de données produites. On appelle cela la contre-pression.
Pour comprendre cela, on crée un publisher de plusieurs données, donc de type Flux. Ensuite on y souscrit en passant un CustomSubscriber (1). Un subscriber a pour rôle de consommer des données. Ce subscriber définit qu’il veut récupérer 2 données, qu’il affiche ensuite à chaque appel de sa méthode onNext() (2).
Flux.fromIterable(listOf("Paris", "London", "Edinburgh", "Los Angeles", "San Francisco", "Atlanta", "New-York")).subscribe(CustomSubscriber()) <1>
class CustomSubscriber : Subscriber<String> {
private lateinit var subscription: Subscription
override fun onSubscribe(incomingSubscription: Subscription?) {
if(incomingSubscription != null){
subscription = incomingSubscription
}
subscription.request(2)
}
override fun onNext(next: String?) { <2>
println("Next destination $next")
}
override fun onError(p0: Throwable?) {
println("Error received")
}
override fun onComplete() {
println("Completed!")
}
}On constate qu’on passe exactement deux fois dans le onNext() avec la sortie suivante:
Next destination Paris
Next destination LondonLe subscriber décide s’il veut recevoir de nouvelles données. Imaginons que notre subscriber réalise une opération longue dans le onNext(), comme un appel réseau, il pourra signaler au publisher en amont d’envoyer moins de données.
Nous pouvons résumer le principe de Reactor ainsi:
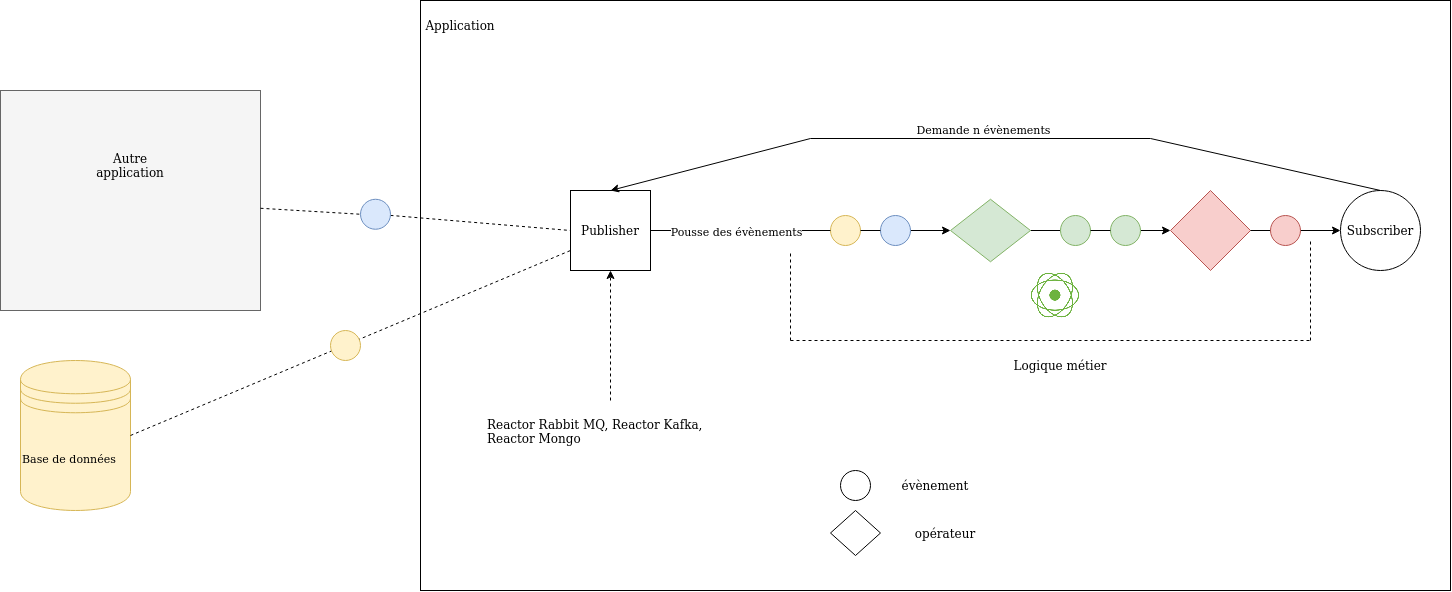
Reactor RabbitMQ
Situation
Prenons l’exemple d’un batch qui doit requêter N destinations de vacances en RPC à un autre service via RabbitMQ. Un appel RPC consiste à envoyer un message à un autre application et à attendre une réponse en retour.
Extrait du batch :
private fun requestHolidayReactive(numberOfRequests: Int) {
val reactiveRpcClient = RabbitFlux.createSender().rpcClient("holiday", "next-holiday-destination") <1>
val countDownLatch = CountDownLatch(numberOfRequests) <2>
Flux.fromIterable((1..numberOfRequests)).map {
RpcClient.RpcRequest(byteArrayOf()) <3>
}.doOnNext {
SENDER_LOGGER.debug("Sending request to holiday service")
}.flapMap { <4>
reactiveRpcClient.rpc(Mono.just(it))
}.doOnNext {
SENDER_LOGGER.debug("Received holiday destination: ${String(it.body)}")
countDownLatch.countDown()
}.log().subscribe() <5>
reactiveRpcClient.close()
countDownLatch.await() <6>
}Dans le code ci-dessus:
-
1 : on crée d’abord un client via la librairie Reactor RabbitMQ en précisant le routage du message : exchange holiday et routing key next-holiday-destination.
-
2 : on crée un
CountDownLatchpour bloquer le thread principal jusqu'à ce que l’ensemble des réponses soient reçues. -
3 : on crée un premier
Publisherde typeFluxqui construit une suite de requêtes. -
4 : L’opérateur
flatMapva lancer les N appels au service des vacances en parallèle via la méthoderpcpuis joindre chaque réponse unitaire de typeMonoen un seulFluxcontenant les N réponses du service des vacances. Le schéma suivant illustre leflapMap. -
5 : On utilise l’utilitaire
.log()de Reactor pour analyser plus en détail les traces et on souscrit au Flux pour déclencher son exécution. -
6 : On bloque jusqu'à ce que toutes le requêtes soient reçues, c’est spécifique au fait d'écrire un batch.
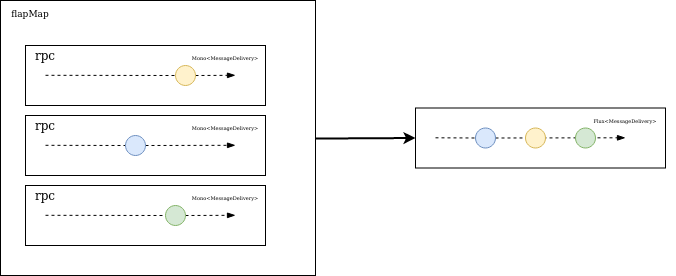
Appel Non bloquant

Thread attendant une réponse du service des vacances
Lançons un appel et observons justement les logs de Reactor :
12:13:10.608 [main] INFO reactor.Flux.Peek.1 - onSubscribe(FluxPeek.PeekSubscriber) <1>
12:13:10.612 [main] INFO reactor.Flux.Peek.1 - request(unbounded)
12:13:10.612 [main] DEBUG Sender - Sending request to holiday service
12:13:10.621 [main] DEBUG Sender - Sending request to holiday service
12:13:10.722 [pool-1-thread-4] DEBUG Sender - Received holiday destination: { "destination": "Rio" } <2>
12:13:10.722 [pool-1-thread-4] INFO reactor.Flux.Peek.1 - onNext(com.rabbitmq.client.Delivery@2f3a5db1) <3>
12:13:10.723 [pool-1-thread-5] DEBUG Sender - Received holiday destination: { "destination": "London" }
12:13:10.723 [pool-1-thread-5] INFO reactor.Flux.Peek.1 - onNext(com.rabbitmq.client.Delivery@74d1f118)Les logs Reactor de l’appel au service des vacances nous montrent bien deux groupes de threads différents: celui sur lequel l’appel au service est fait, qui ne contient que le thread main dans notre cas, et celui sur lequel les réponses du service sont reçues, dont tous les threads sont préfixés par pool-1.
Reactor exécute le code par défaut sur le thread effectuant le susbcribe, on le voit bien avec la première ligne de log onSubscribe() et l’identifiant du thread main (1).
Le deuxième pool pool-1 est interne au reactiveRpcClient. A chaque réponse du service des vacances, un message est poussé dans le pool, le pool se charge alors de trouver un thread (exemple: pool-1-thread-5) pour exécuter les opérateurs définis après le flatMap, c’est dans ce thread qu’est donc logguée la réponse (2).
De cette manière, le thread main est libéré dès lors que le message est envoyé au service de vacances. D’où l’obligation de forcer le thread main à attendre l’exécution de toutes les réponses à la fin de notre batch avec le countDownLatch.await(). Les réponses seront traitées plus tard sur le pool interne au reactiveRpcClient.
Cependant, il faut bien qu’un thread écoute les réponses du service des vacances qui peuvent arriver de manière imprévisible , cela est géré par un seul thread rabbitmq-nio. Il est en charge de dispatcher chaque réponse au pool de thread pool-1. Il est possible de voir ce thread en affichant la liste des threads à la fin de l'éxécution du batch.
15:25:39.933 [main] DEBUG Sender - id=1 group=main name=main state=RUNNABLE
15:25:39.933 [main] DEBUG Sender - id=18 group=main name=pool-1-thread-2 state=TIMED_WAITING
15:25:39.933 [main] DEBUG Sender - id=19 group=main name=pool-1-thread-3 state=WAITING
15:25:39.933 [main] DEBUG Sender - id=20 group=main name=pool-1-thread-4 state=WAITING
15:25:39.933 [main] DEBUG Sender - id=22 group=main name=pool-1-thread-5 state=WAITING
15:25:39.934 [main] DEBUG Sender - id=17 group=main name=rabbitmq-nio state=RUNNABLE
15:25:39.934 [main] DEBUG Sender - id=16 group=main
name=rabbitmq-sender-connection-subscription-1 state=WAITINGOn peut résumer le fonctionnement de l’appel rpc ainsi:
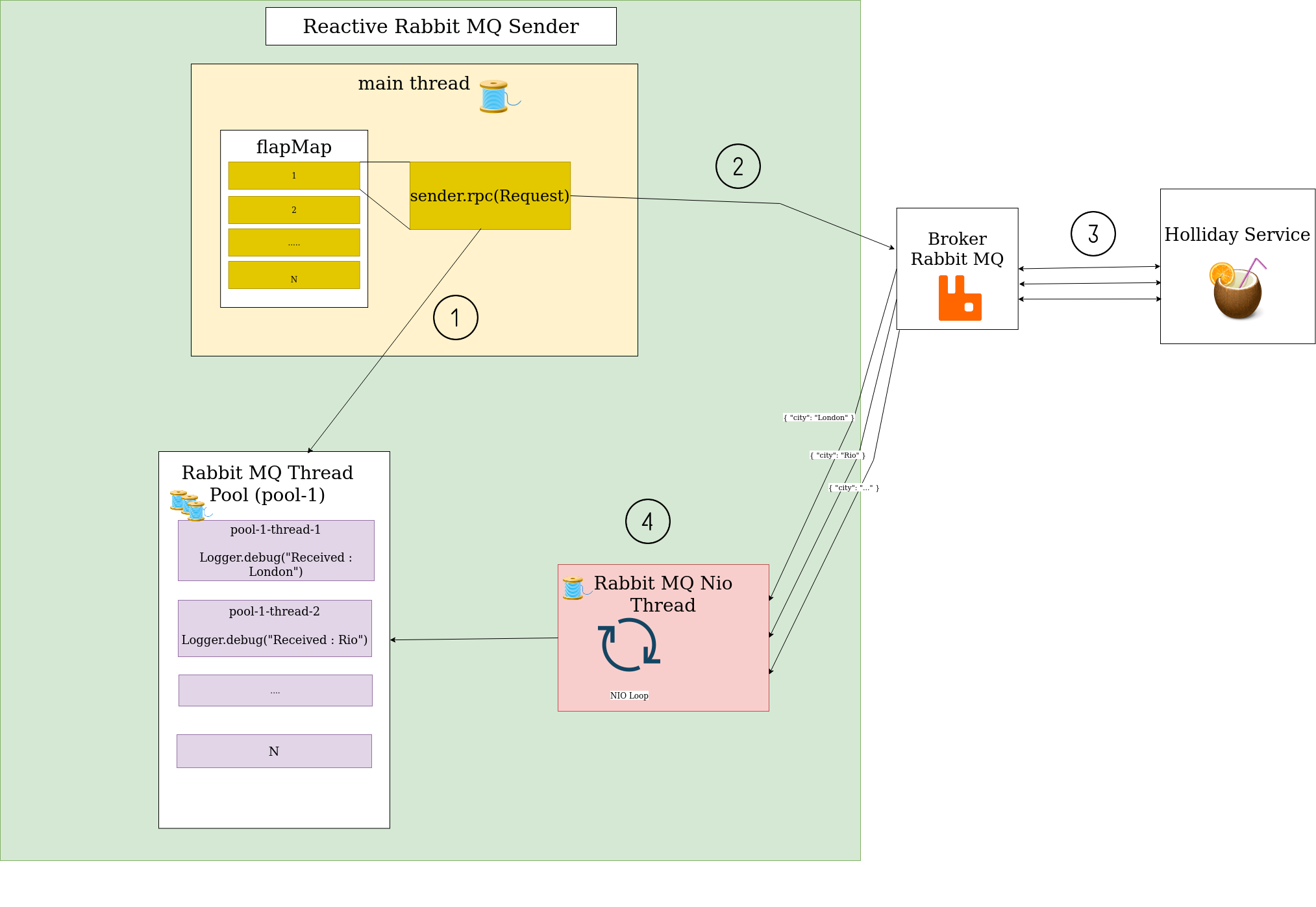
-
1: Le thread principal appelle la méthode rpc qui enregistre un callback dans le pool de thread dédié de Reactor RabbitMQ.
-
2: Le thread principal envoie en parallèle les requêtes grâce à l’opérateur
flatMap. -
3: le service des vacances répond à chaque message.
-
4: Ensuite, le thread RabbitMQ NIO, reçoit les messages et soumet au pool de thread le contenu du message accompagné d’un identifiant de corrélation pour retrouver le callback correspondant à chaque réponse. Le callback est ensuite exécuté lorsqu’un un thread est disponible dans le pool.
Après avoir vu comment Reactor RabbitMQ peut-être utilisé dans un contexte non-bloquant.
Gestion de la contre-pression entre les deux services
Nous allons voir ici comment Reactor permet de remonter la contre-pression entre les deux services. Nous pouvons relancer le batch en demandant 100 destinations de vacances et en rajoutant un temps de latence de 500 ms dans le service des destinations. On obtient alors, via l’interface d’administration RabbitMQ, le graphe de la quantité de messages en attente de traitement par le service de destinations de vacances :
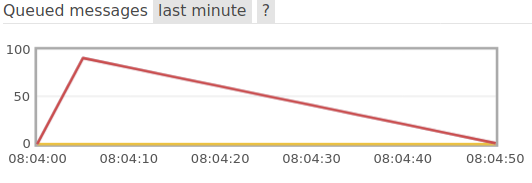
Graphe des messsages en attente de traitement par le service des vacances si utilisation du flatMap
On observe une augmentation subite du nombre de messages et un certain temps pour les dépiler. Dans ce cas là, le service des destinations est saturé par les demandes, on voit bien qu’il faut plus de 50 secondes pour traiter tout les messages. En utilisant l’opérateur concatMap de Reactor plutôt que flatMap on observe maintenant le graphe suivant:
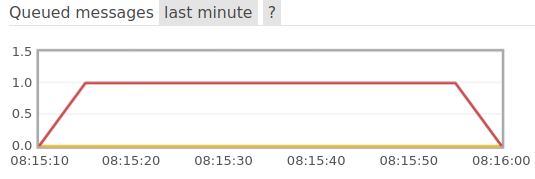
Graphe des messsages en attente de traitement par le service des vacances si utilisation du concatMap
On observe que le service n’a pas été saturé. Un seul message à la fois est resté en attente de traitement. Le batch a respecté le rythme de traitement du service des destinations de vacances.
Explication
Les opérateurs concatMap et flatMap permettent tous les deux de souscrire en parallèle à plusieurs publishers. Dans notre cas, le concatMap et le flapMap déclenchent donc en parallèle les appels au service des vacances en souscrivant plusieurs fois au retour de la méthode rpc. D’où la réception simultané de 100 messages dès le début du batch dans le cas du flapMap.
La différence du concatMap, est la présence d’un compteur du nombre de publishers en état complete qui, après avoir dépassé une certaine taille, lance de nouveaux des souscriptions aux publishers suivants.
Autrement dit, il lance un premier batch d’appels au service des vacances, exécute le code à réaliser avec toutes toutes les réponses reçues et seulement ensuite, lance un nouvelle suite d’appels.
L’opérateur concatMap évite à la fois de saturer le service des vacances et tout autre composant réactif qui serait appelé à la réception du message. Par exemple, le batch pourrait insérer en base de données chaque destination reçue, si la base est saturée, le batch ralentira de lui-même la cadence. Les opérateurs de Reactor peuvent donc comme les Subscribers, influer sur le nombre de nouveaux éléments que le Publisher doit envoyer et assurer une remontée de la contre-pression au Publishers.
Grâce à la remontée de la contre-pression, notre batch évitera au service des destinations de vacances de crouler sous les requêtes!

Thread libéré
D’autres fonctionnalités de Reactor RabbitMQ
En plus des appels RPC, d’autres cas d’usages sont possible en réactif comme :
-
déclarer des topologies (exchanges, queues, routages)
-
consommer les messages
-
publier des évènements sans attendre de réponse
-
publier avec confirmation
Conclusion
Reactor RabbitMQ tire parti de Reactor pour permettre d’avoir une application non bloquante et avec une prise en compte de la contre-pression. Les applications utilisant déjà Reactor, notamment les serveurs HTTP comme Reactor Netty, peuvent maintenant être réactives de bout en bout également avec RabbitMQ.
sources :